

Anfang 2025 prägte Andrej Karpathy den Begriff „Vibe Coding": Man beschreibt grob, was man will, die KI generiert den Code, man akzeptiert das Ergebnis weitgehend ungeprüft – und irgendwie funktioniert es. Der Ansatz traf einen Nerv, weil er ein echtes Gefühl beschreibt: Mit LLMs wie ChatGPT, Claude oder Copilot lässt sich in Minuten zusammenbauen, wofür man früher Stunden oder Tage gebraucht hätte.
Wer länger in der Softwareentwicklung unterwegs ist, erkennt darin den nächsten Schritt einer Entwicklung, die seit Jahrzehnten läuft. Wir haben uns schon immer Hilfe geholt – aus Büchern, Foren, Stack Overflow, Tutorials. Was sich verändert hat, ist nicht die Hilfe an sich, sondern ihr Autonomiegrad: Statt Antworten nachzuschlagen, delegieren wir heute ganze Arbeitspakete.
Genau das macht Vibe Coding so verführerisch und gleichzeitig so riskant, sobald es über den Prototyp hinausgeht. Die Antwort darauf ist nicht weniger KI, sondern besser geführte KI – und genau das ist die Idee hinter Agentic Coding. In unseren Projekten bei pentacor haben wir über mehrere Wochen ausprobiert, wie man diesen Produktivitätsschub nutzen kann, ohne die Kontrolle zu verlieren. Dieser Artikel ist unser Erfahrungsbericht: Was funktioniert? Wo liegen die Grenzen? Und wie führt man die KI so, dass am Ende kein Zufall steht, sondern verlässliche Ergebnisse erzielt werden?
Warum Vibe Coding im Team kippt
Vibe Coding ist als Einstiegsmodus nett und in der richtigen Situation großartig: schnell eine Idee testen, explorativ prototypen, „mal eben“ einen Spike bauen. Im Team und auf Dauer entsteht dabei aber oft eine ungünstige Mischung: Annahmen bleiben implizit, Konventionen werden mal eingehalten und mal ignoriert, Tests und Randfälle rutschen durch, Qualitätsanforderungen inklusive Security werden spät oder gar nicht adressiert. Das Ergebnis ist selten sauberer Fortschritt, sondern ein schleichender Verfall Richtung Big Ball of Mud – wie bisher auch, ohne klare Architektur, nur diesmal schneller.
Das liegt weniger an schlechten Prompts als an einem strukturellen Problem: Was im Prompt landet, ist immer nur ein Bruchteil des relevanten Kontexts. Business Intent, gewachsene Anforderungen, Architekturentscheidungen, Team-Konventionen, Runtime-Umgebung, History – all das existiert, fließt aber nicht in den Prompt ein. Die KI arbeitet mit dem, was sie bekommt, und füllt den Rest mit plausiblen Annahmen. Plausibel heißt dabei nicht richtig.
Oder bildlich gesprochen: Vibe Coding ist wie Stöckchen werfen – der Hund rennt los, kommt vielleicht zurück, vielleicht mit dem Stock, vielleicht mit einem Kaninchen, und manchmal verschwindet er einfach im Wald. Agentic Coding nimmt den Hund an die Leine und setzt genau dort an. Es versucht nicht, Vibe Coding zu skalieren, sondern es durch Wiederholbarkeit und Kontrolle zu ersetzen. Die Grundidee: Der Mensch definiert Ziel und Rahmen, die KI übernimmt das Wie – aber entlang eines klaren Prozesses mit erwarteten Artefakten. Statt „mach mal" heißt es dann: Plane, setze um, prüfe dich selbst, liefere Review-Hinweise, iteriere gezielt!
Der eigentliche Paradigmenwechsel: von Code zu Steuerung
Der größte Shift passiert auf der Abstraktionsebene. Ein Teil der Engineering-Arbeit wandert von „Code schreiben“ zu „Ziele, Rahmenbedingungen und Workflows formulieren“. Gute Ergebnisse kommen selten aus einem cleveren Prompt, sondern aus klaren Akzeptanzkriterien, sauberer Kontextabgrenzung, expliziten Qualitätsanforderungen und einem Prozess, der die typischen Fehlerquellen abfängt. Das ist auch der Punkt, an dem Human-in-the-loop praktisch wird: nicht als „wir schauen am Ende kurz drüber“, sondern als Quality-Gate mit Freigaben und klaren Checkpoints.
Kurz gesagt: Wir nehmen die KI an die virtuelle Leine und führen sie von Anforderung zu Code, Test und Review.
Erfahrung aus der Praxis
In der Praxis funktioniert Agentic Coding dann gut, wenn der Mensch Dinge wie Scope, Kontext und Done-Kriterien vorgibt. Der Agent arbeitet entlang eines wiederholbaren Musters:
- Plan: Vorgehen, offene Fragen, Risiken, Annahmen
- Umsetzung: nachvollziehbar in kleinen Schritten, idealerweise als Diff
- Self-Checks: Tests, Lints, einfache Security-Checks, statische Analysen, wo sinnvoll
- Review-Notizen: Was wurde warum geändert? Worauf sollte ein Reviewer achten?
Damit das verlässlich klappt, braucht es die „Leine“ für die LLM: einen minimalen Workflow, bestehend aus einem Ablauf, einer Review-Checkliste und der Definition of Done.
Der Ablauf definiert, welche Artefakte der Agent liefert (Plan, Diff, Tests, Notizen). Die Checkliste beschreibt, was geprüft wird (Funktionalität, Tests, Qualitätskriterien, Konventionen, Verständlichkeit). Die DoD legt fest, wann wirklich Schluss ist.
Das wirkt zunächst prozesslastig, spart aber Zeit: weniger zufällige Schleifen, weniger Nacharbeit, stabilere Ergebnisse.
Besonders wertvoll wird Agentic Coding, wenn die KI nicht nur „neuen Code“ erzeugt, sondern auch die ungeliebten, aber wichtigen Aufgaben beschleunigt: Projektsteckbrief erstellen, Dokumentation aktualisieren, Release Notes vorbereiten, Refactor-Listen strukturieren, Testideen ableiten oder Review-Checklisten durchgehen. Nebenbei ist das ein starker Lernhebel für Juniors, weil explizit wird, worauf es ankommt: dokumentierte Anforderungen mit Akzeptanzkriterien, Naming, Tests, Risiken und Architektur-Checks.
Zwei „Leinen“ aus der Praxis
In unseren Projekten haben wir über mehrere Wochen zwei sehr unterschiedliche Ansätze ausprobiert.
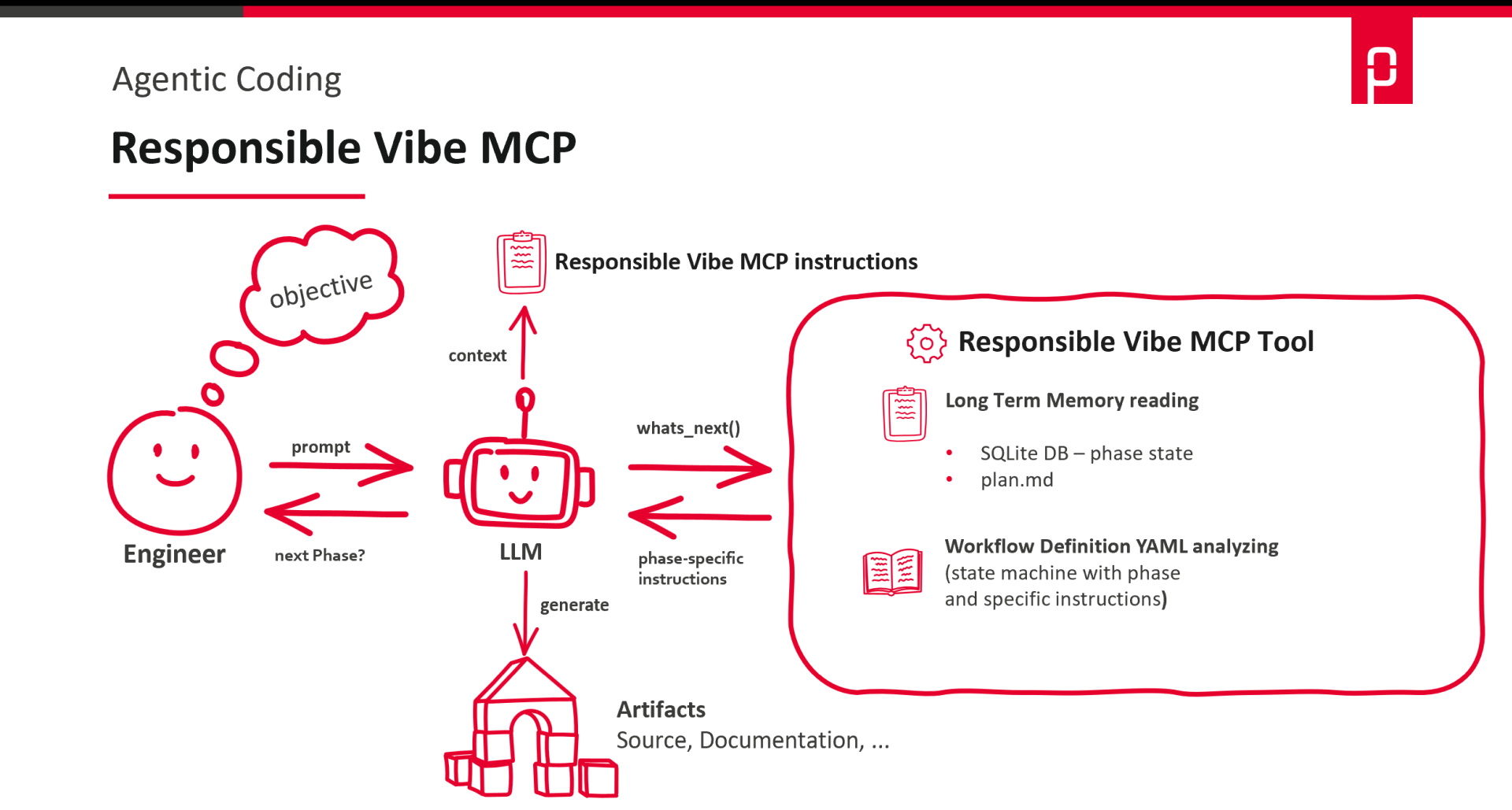
Responsible Vibe MCP: leichtgewichtig, schnell startklar
Responsible Vibe MCP ist bewusst schlank gehalten und schnell einsatzbereit. Die Stärke liegt in der klaren Führung durch vorab definierte Workflows mit Kontrollpunkten, ohne gleich ein komplettes „Framework-Universum“ mitzubringen. Workflows werden als YAML-Dateien definiert und legen explizit fest, in welchem Schritt eine Aufgabe abgearbeitet wird – etwa Planung, Umsetzung, Self-Check und Review – inklusive konkreter Erwartungen und Definition of Done. Jeder Schritt kann damit als Review-Punkt genutzt werden. Das Prinzip ähnelt strukturiertem Pair Programming – nur formalisiert und wiederholbar. Der Mensch definiert Workflow, Checklist und DoD, der Agent arbeitet diese Leitplanken diszipliniert ab.
Ausprobiert haben wir es zur Erweiterung einer eventgetriebenen PV-Steuerungsapplikation auf Kotlin-Basis, bei der Modernisierung einer älteren OpenGL-basierten Python-Anwendung und beim Bugfixing einer über Jahre gewachsenen Spring-Boot-Applikation.
Der Ansatz funktioniert besonders gut bei kleinen bis mittleren, klar abgegrenzten Aufgaben: Bugfixes, Ref.actorings, oder Dokumentationsupdates. Er lässt sich einfach teamspezifisch zuschneiden, etwa durch eigene Checklisten und eine angepasste DoD, und ist bei der Nutzung transparent.
Mit dem Aufkommen moderner skillbasierter Agentenmodelle, die dynamisch zwischen spezialisierten Fähigkeiten wechseln, könnte dieser eher statische Workflow-Ansatz perspektivisch ergänzt oder teilweise abgelöst werden.
Weitere Informationen zu Responsbile Vibe MCP findet ihr in einem unserer Lieblingspodcasts “Software Architektur im Stream”.
Hier eine Übersicht, wie eine Aufgabe mittels Responsible Vibe MCP abgearbeitet wird.
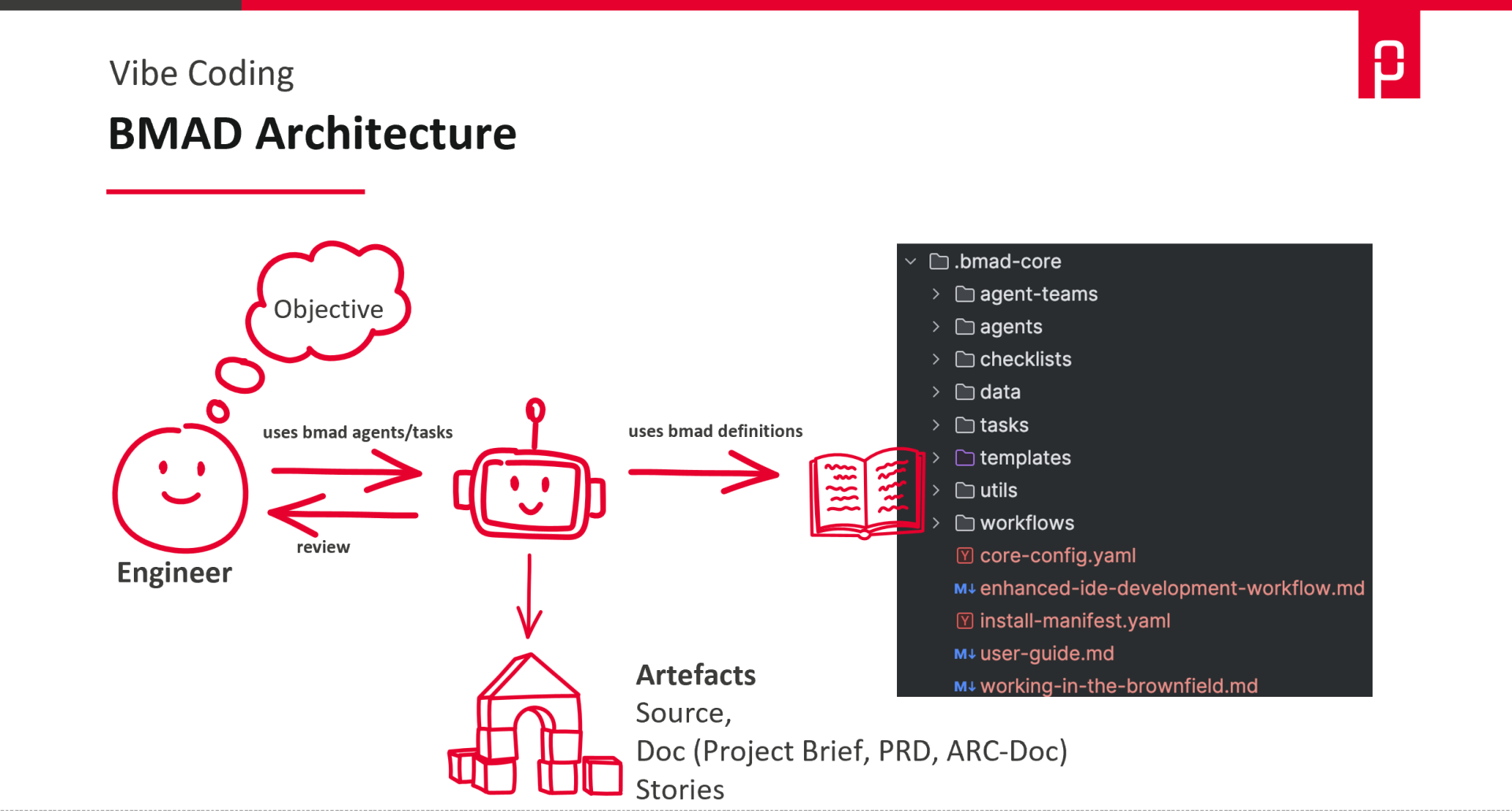
BMAD: Rollen, Workflows, „DevOps-Team in Agentenform“
BMAD (Breakthrough Method of Agile AI-Driven Development) ist das andere Ende des Spektrums. Es bringt ein ganzes Rollen-Set und Workflows mit, konkret Agenten für typische Projektrollen: Analyst, PM, Architekt, Product Owner, Scrum Master, Developer und QA. Jede Rolle hat eigene Aufgaben und Anweisungen – der Analyst klärt das Problem, der PM sammelt Requirements, der Architekt trifft Technologieentscheidungen, der PO schneidet Stories, der Developer setzt um, QA testet. Der Mensch bleibt Supervisor, priorisiert und entscheidet, und kann jede Rolle auch selbst übernehmen.
Ein typischer Greenfield-Flow sieht dann so aus: Der Analyst erarbeitet ein Project Brief, der PM leitet daraus ein Product Requirements Document ab, der Architekt erstellt die Architekturdokumentation, der PO validiert beides und schneidet Epics und Stories mit Akzeptanzkriterien, der Scrum Master detailliert die Stories für die Entwicklung, der Developer implementiert, und QA prüft gegen die Anforderungen. Nicht jedes Projekt braucht den vollen Flow – einzelne Rollen und Phasen lassen sich auch gezielt einsetzen.
Hier ein kleiner Überblick, was BMAD mitbringt.
Der große Vorteil liegt weniger in der schnellen Codeänderung als in der sauberen Vorarbeit: Requirements klären, Fragen stellen, Struktur reinbringen, Konzepte erarbeiten, Stories schneiden. BMAD ist damit besonders stark bei Aufgaben, die sonst gern chaotisch werden, weil Kontext und Erwartungen unklar sind.
In unserem Umfeld nutzten wir es bei der Erstellung einer cloudnativen Architektur im IoT-Bereich und bei einer Anforderungsanalyse mit Ableitung eines Architekturkonzepts. Gerade hier war die Planungsphase beeindruckend: Brainstorming, Projektsteckbrief und Requirements-Analyse lieferten in kurzer Zeit Ergebnisse, für die wir manuell deutlich länger gebraucht hätten – und die Qualität der Fragen und Strukturvorschläge war durchweg hoch. In einem anderen Kontext setzten wir BMAD für die Umsetzung eines einfachen CLI-Prototyps ein. Hier zeigte sich, dass bei der eigentlichen Code-Generierung mehr Aufmerksamkeit gefragt ist: Ohne enge Führung und klare Checkpoints neigt der Agent dazu, Vorgaben aus den Rahmenbedingungen zu übersehen oder großzügig zu interpretieren.
Der Nachteil ist der gleiche wie bei vielen „vollständigen" Methoden: Für kleine Tasks wirkt es schnell zu schwergewichtig, und der Output kann ausufern. Der Mehrwert entsteht nur, wenn das Team konsequent kuratiert, kürzt und fokussiert.
Wo Licht ist, ist auch Schatten
So überzeugend das alles klingen mag: Ein paar Grenzen sind aktuell sehr real. Team-Fit und Customization kosten Zeit, weil Rollen, Checklisten und Done-Kriterien definiert, gepflegt und weiterentwickelt werden müssen.
Context-Limits bleiben ein echtes Risiko: Zu große Tasks führen zu falschen Annahmen, inkonsistenten Änderungen und vergessenen Randbedingungen. Garbage in, Garbage out ist dabei besonders bösartig, weil der Output oft glaubwürdig wirkt.
Debugging-Fehler sind nicht mehr nur Code-Fehler, sondern häufig auch Prompt-, Workflow- oder Kontextfehler. Dadurch wird die Traceability von Anforderung → Entscheidung → Code noch wichtiger.
Kosten sind ein weiterer Faktor: Multi-Agent-Workflows, lange Kontexte und viele Iterationen werden schnell teuer. Und Security ist nicht optional: Security-Guidelines gelten nicht nur für den generierten Code, sondern auch für Tool-Zugriffe und Datenflüsse des Agents. Output gehört grundsätzlich ins Review – nicht direkt in den Merge.
Zu guter Letzt kann auch der von uns so geliebte Flow leiden, wenn man zu viele Prompt-Schleifen drehen muss und das Gefühl bekommt, zum Dauer-Reviewer für mittelmäßigen Code zu werden. Dann gilt: Korrekturhinweise nicht nur in den Code zurückspielen, sondern konsequent in Checklisten, DoD und den Ablauf.
Fazit: Autonomie ja – aber geführt
Unterm Strich funktioniert Agentic Coding sowohl in klassischen IDE-Setups als auch mit AI-first Tools wie Claude Code. Der Produktivitätsschub ist real, aber nur dann nachhaltig, wenn man ihn nicht dem Zufall überlässt. „Mit Leine“ ist dabei keine Spießerregel, sondern die Voraussetzung, dass Autonomie nicht in Overengineering, Halluzinationen oder Security-Albträumen endet. Die Kernaussage ist für uns: Agentic Coding soll Kontrolle und Wiederholbarkeit in KI-gestützte Entwicklung bringen.
Wer pragmatisch starten will, braucht keinen großen Umbau: einen kleinen, wiederholbaren Workflow, eine Review-Checklist und eine klare DoD. Wenn das im Team sitzt und sich „gut anfühlt“, kann man auf größere Aufgaben, mehr Rollen und mehr Tooling skalieren. Genau dann wird aus KI-Hilfe ein verlässlicher Engineering-Baustein.



