

In early 2025, Andrej Karpathy introduced the term “vibe coding”: You roughly describe what you want, the AI generates the code, you accept the result mostly without checking it – and somehow it works. This approach struck a chord because it captures a genuine feeling: with LLMs like ChatGPT, Claude, or Copilot, it takes minutes to put something together that used to take hours or days.
Anyone with experience in software development will recognize this as the next step in a trend that has been unfolding for decades. We’ve always sought help – from books, forums, Stack Overflow, and tutorials. What changed is not the help itself, but the degree of autonomy it offers: Instead of looking up answers, we now delegate entire workflows.
That is precisely what makes Vibe Coding both appealing and risky once it moves beyond the prototype stage. The answer isn’t more AI, but better-guided AI – and that is exactly the idea behind Agentic Coding. In our projects at pentacor, we spent several weeks experimenting with how to leverage this productivity boost without losing control. This article is our report of our experiences: What works? Where are the limits? And how do you guide AI so that the end result isn’t left to luck, but rather delivers reliable outcomes?
Vibe Coding in Teams: It's complicated
Vibe coding is a nice way to get started and works great in the right situation: quickly testing an idea, exploratory prototyping, or “just” building a spike. In a team setting and in the long run however, this often leads to an unfavorable mix: assumptions remain implicit, conventions are sometimes followed and sometimes ignored, tests and edge cases slip through the cracks, and quality requirements—including security—are addressed late or not at all. The result is rarely clean progress, but rather a creeping decline toward a big ball of mud – just like before, without clear architecture, only this time faster.
It's not so much a matter of poor prompts as it is a structural problem: what ends up in the prompt is always just a fraction of the relevant context. Business intent, evolving requirements, architectural decisions, team conventions, runtime environment, history – all of these exist, but they aren't included in the prompt. AI can only work with what the user is providing and fills in the rest with plausible assumptions. In this context, “plausible” doesn’t mean “correct.”
Or to put it another way: Vibe Coding is like playing fetch – the dog runs off, might come back, maybe with the stick, maybe with a rabbit, and sometimes it just disappears into the woods. Agentic Coding puts the dog on a leash and starts from there. It doesn’t try to scale Vibe Coding, but rather replaces it with repeatability and control. The basic idea: Humans define the goal and the framework; AI handles the “how” – but along clearly defined processes with expected deliverables. Instead of “just do it,” the approach is: Plan, implement, self-assess, provide feedback, and iterate purposefully!
The real paradigm shift: from code to control
The biggest shift is happening at the level of abstraction. Part of the engineering work is shifting from “writing code” to “defining goals, parameters, and workflows.” Good results rarely result from clever prompts, but rather from clear acceptance criteria, well-defined context boundaries, explicit quality requirements and a process that prevents common sources of error. This is also where “human-in-the-loop” comes into play: not as a “quick final review,” but as a quality gateway with approvals and clear checkpoints.
In short: We put the AI on a virtual leash and guide it from requirements to code, testing, and review.
Hands-on experience
In reality, agentic coding works well when people define things like scope, context, and acceptance criteria. The agent works according to a repeatable pattern:
- Plan: Approach, open questions, risks, assumptions
- Implementation: Traceable in small steps, ideally as a diff
- Self-checks: Tests, lints, simple security checks, static analyses where appropriate
- Review notes: What was changed and why? What should a reviewer look for?
To ensure this works reliably, the LLM needs a “leash”: a minimal workflow consisting of a procedure, a review checklist, and the Definition of Done.
The process defines which artifacts the agent delivers (plan, diff, tests, notes). The checklist describes what is checked (functionality, tests, quality criteria, conventions, clarity). The DoD specifies when the work is truly complete.
At first, this may seem process-heavy, but it actually saves time: fewer random loops, less rework and more reliable results.
Agentic Coding is particularly useful when AI not only generates “new code” but also speeds up those unpopular yet important tasks: creating project profiles, updating documentation, preparing release notes, structuring refactoring lists, deriving test ideas, or going through review checklists. Incidentally, this is a powerful learning tool for junior developers because it highlights what really matters: documented requirements with acceptance criteria, naming conventions, tests, risks, and architecture checks.
Two “leashes” from the real world
In unseren Projekten haben wir über mehrere Wochen zwei sehr unterschiedliche Ansätze ausprobiert.
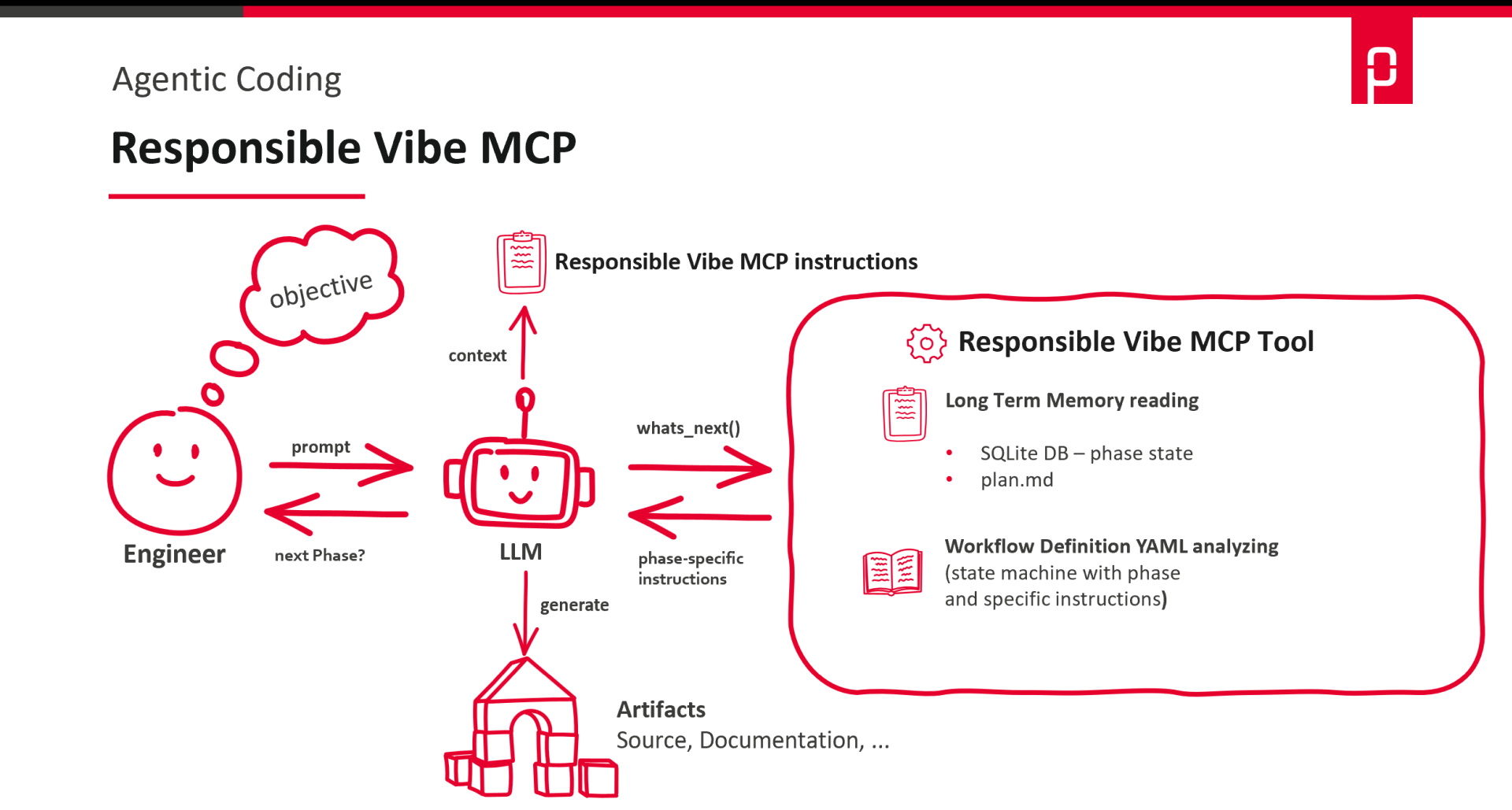
Responsible Vibe MCP: Lightweight, quick setup
Responsible Vibe MCP is intentionally kept lean and is quick to deploy. Its strength lies in clear guidance through predefined workflows with checkpoints, without requiring a complete “framework ecosystem.” Workflows are defined as YAML files and explicitly specify the step in which a task is processed – such as planning, implementation, self-check, and review – including concrete expectations and a Definition of Done. Each step can thus be used as a review point. The principle resembles structured pair programming – only formalized and repeatable. The user defines the workflow, checklist, and DoD. The agent follows these guidelines in a disciplined manner.
We put it to the test when extending an event-driven Kotlin-based PV control application, when modernizing an older OpenGL-based Python application and when fixing bugs in a Spring Boot application that had grown over the years.
This approach works particularly well for small to medium-sized, clearly defined tasks: bug fixes, refactorings or documentation updates. It can be easily tailored to specific teams – for example, through custom checklists and a customized Definition of Done – and is transparent in its application.
With the emergence of modern skill-based agent models that dynamically switch between specialized skills, this relatively static workflow approach could eventually be supplemented or partially replaced.
You can find more information about Responsbile Vibe MCP on one of our favorite podcasts “Software Architektur im Stream”.
Here is an overview of how a task is processed using Responsible Vibe MCP.
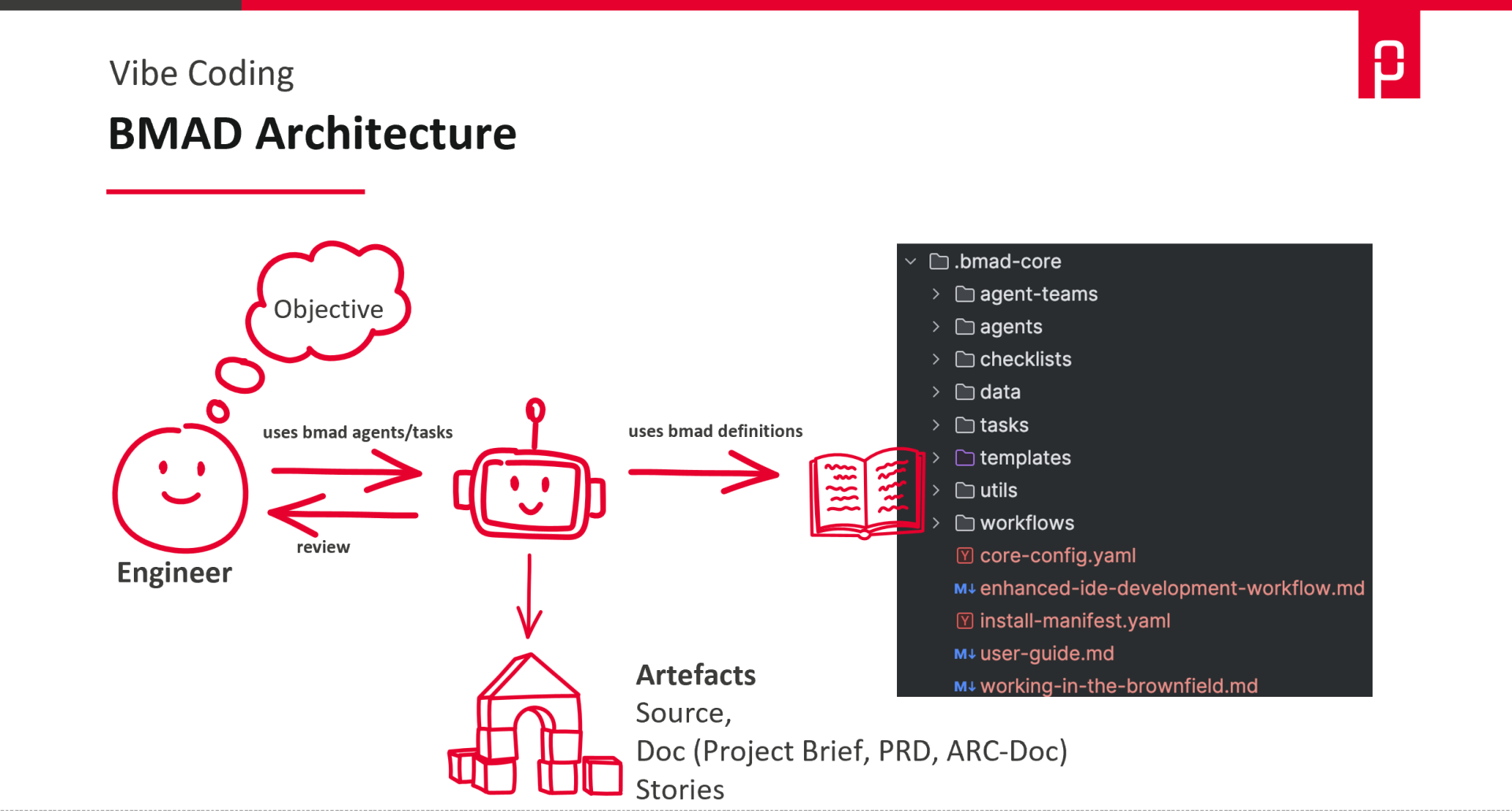
BMAD: Roles, Workflows, “DevOps Team in Agent Form”
BMAD (Breakthrough Method of Agile AI-Driven Development) represents the other end of the spectrum. It comes with a complete set of roles and workflows, specifically agents for typical project roles: Analyst, PM, Architect, Product Owner, Scrum Master, Developer, and QA. Each role has its own tasks and instructions – the analyst defines the problem, the PM gathers requirements, the architect makes technology decisions, the PO breaks down stories, the developer implements and QA tests. The human remains the supervisor, prioritizes, and makes decisions and can also take on any role themselves.
A typical Greenfield workflow looks like this: The analyst develops a project brief; the PM uses this to create a product requirements document; the architect prepares the architectural documentation; the PO validates both and breaks them down into epics and stories with acceptance criteria; the Scrum Master refines the stories for development; the developer implements the code; and QA tests it against the requirements. Not every project needs the full flow – individual roles and phases can also be deployed selectively.
Here’s a brief overview of what BMAD has to offer.
The main advantage lies less in the speed of code changes than in thorough preparatory work: clarifying requirements, asking questions, establishing structure, developing concepts, and breaking down user stories. BMAD is therefore particularly effective for tasks that would otherwise tend to become chaotic due to unclear context and expectations.
In our context, we used it to build a cloud-native architecture in the IoT sector and to conduct a requirements analysis that led to the development of an architectural concept. The planning phase was particularly impressive here: brainstorming, project profiles, and requirements analysis delivered results in a short amount of time – results that would have taken us significantly longer to achieve manually – and the quality of the questions and structural suggestions was consistently high. In another context, we used BMAD to implement a simple CLI prototype. Here, it became apparent that more attention is needed during the actual code generation: without close guidance and clear checkpoints, the agent tends to overlook or generously interpret specifications from the framework conditions.
The downside is the same as with many “comprehensive” methods: for small tasks, it can quickly feel too bulky and the output can become overwhelming. The added value only materializes if the team consistently curates, streamlines, and focuses.
Where there is light, there is also shadow
As convincing as all this may sound, there are currently some very real limitations. Team fit and customization take time because roles, checklists, and acceptance criteria need to be defined, maintained, and refined.
Context limits remain a real risk: Tasks that are too large lead to incorrect assumptions, inconsistent changes, and overlooked constraints. “Garbage in, garbage out” is particularly malicious in this case because the output often appears credible.
Debugging errors are no longer just code errors; they are often prompt, workflow, or context errors as well. This makes traceability from requirement → decision → code even more important.
Costs are another factor: multi-agent workflows, long contexts and numerous iterations can quickly become expensive. And security is not optional: security guidelines apply not only to the generated code, but also to tool access and the agent’s data flows. Output should always be included in the review – not merged directly into the repository.
Last but not least, even the flow we love so much can suffer if you have to go through too many rounds of prompts and start feeling like you’re becoming a permanent reviewer of mediocre code. In that case, the rule is: don’t just incorporate feedback into the code, but consistently apply it to checklists, the DoD and the workflow.
Conclusion: Autonomy, yes – but guided
The point is, agentic coding works just as well in traditional IDE setups as it does with AI-first tools like Claude Code. The productivity boost is real, but it’s only sustainable if you don’t leave it to chance. “Keeping it on a leash” is not a rigid rule here but rather the prerequisite for ensuring that autonomy does not end in overengineering, hallucinations or security nightmares. The key takeaway for us is this: Agentic Coding is intended to bring control and repeatability to AI-assisted development.
If you want to take a pragmatic approach, you don’t need a major overhaul: just a small, repeatable workflow, a review checklist and a clear definition of done. Once the team has this down and it “feels right,” you can scale up to larger tasks, more roles and more tools. That’s exactly when AI assistance becomes a reliable engineering building block.



